<?php
if ( ! defined( 'ABSPATH' ) ) {
exit;
}
function voxel_common_user_timeline_words_shortcode( $atts ) {
global $wpdb, $post;
// Set default shortcode attributes.
$atts = shortcode_atts(
[
'limit' => 10, // Maximum number of phrases to display.
'user_id' => 0, // Specific user ID (optional).
],
$atts,
'common_user_timeline_words'
);
// Get the current user ID if not provided.
$user_id = ! empty( $atts['user_id'] ) ? intval( $atts['user_id'] ) : get_current_user_id();
// Prepare the query to fetch timeline posts.
$table_name = $wpdb->prefix . 'voxel_timeline';
$query = "SELECT content FROM $table_name WHERE feed = 'user_timeline'";
if ( $user_id ) {
$query .= " AND user_id = $user_id";
}
$results = $wpdb->get_results( $query );
// We count each unigram and bigram once per post.
$unigram_counts = [];
$bigram_counts = [];
// Define an array of common stop words to exclude.
$stop_words = [
'the', 'and', 'a', 'an', 'to', 'of', 'in', 'it', 'is',
'that', 'this', 'i', 'for', 'on', 'with', 'as', 'was',
'but', 'are', 'be', 'by', 'not', 'have', 'had', 'or', 'at',
'from', 'you', 'your', 'they', 'we', 'which'
];
// Process each post.
foreach ( $results as $result ) {
// Normalize post content.
$content = strtolower( strip_tags( $result->content ) );
// Remove punctuation (only allow letters, numbers, and whitespace).
$content = preg_replace( "/[^\w\s]/", '', $content );
// Split content into words.
$words = preg_split( '/\s+/', $content, -1, PREG_SPLIT_NO_EMPTY );
// Filter out stop words.
$filtered = array_filter( $words, function( $word ) use ( $stop_words ) {
return ! in_array( $word, $stop_words, true );
});
$filtered = array_values( $filtered ); // reindex
// Get unique unigrams for this post.
$unique_unigrams = array_unique( $filtered );
// Tally each unique unigram.
foreach ( $unique_unigrams as $uni ) {
if ( ! isset( $unigram_counts[ $uni ] ) ) {
$unigram_counts[ $uni ] = 0;
}
$unigram_counts[ $uni ]++;
}
// Generate bigrams (two-word phrases) from the filtered words.
$bigrams = [];
$count_words = count( $filtered );
for ( $i = 0; $i < $count_words - 1; $i++ ) {
$bigram = $filtered[$i] . ' ' . $filtered[$i + 1];
$bigrams[] = $bigram;
}
// Get unique bigrams for this post.
$unique_bigrams = array_unique( $bigrams );
// Tally each unique bigram.
foreach ( $unique_bigrams as $bi ) {
if ( ! isset( $bigram_counts[ $bi ] ) ) {
$bigram_counts[ $bi ] = 0;
}
$bigram_counts[ $bi ]++;
}
}
// Filter out phrases that appear in only one post.
$unigram_counts = array_filter( $unigram_counts, function( $count ) {
return $count > 1;
});
$bigram_counts = array_filter( $bigram_counts, function( $count ) {
return $count > 1;
});
// Remove unigrams that are part of any bigram in our final list.
foreach ( $bigram_counts as $bigram => $bcount ) {
$parts = explode( ' ', $bigram );
foreach ( $parts as $part ) {
if ( isset( $unigram_counts[ $part ] ) ) {
unset( $unigram_counts[ $part ] );
}
}
}
// Merge bigrams and unigrams.
$merged = array_merge( $unigram_counts, $bigram_counts );
// Sort by frequency in descending order.
arsort( $merged );
// Limit to the specified count.
$merged = array_slice( $merged, 0, intval( $atts['limit'] ), true );
// Build the output using a styled span.
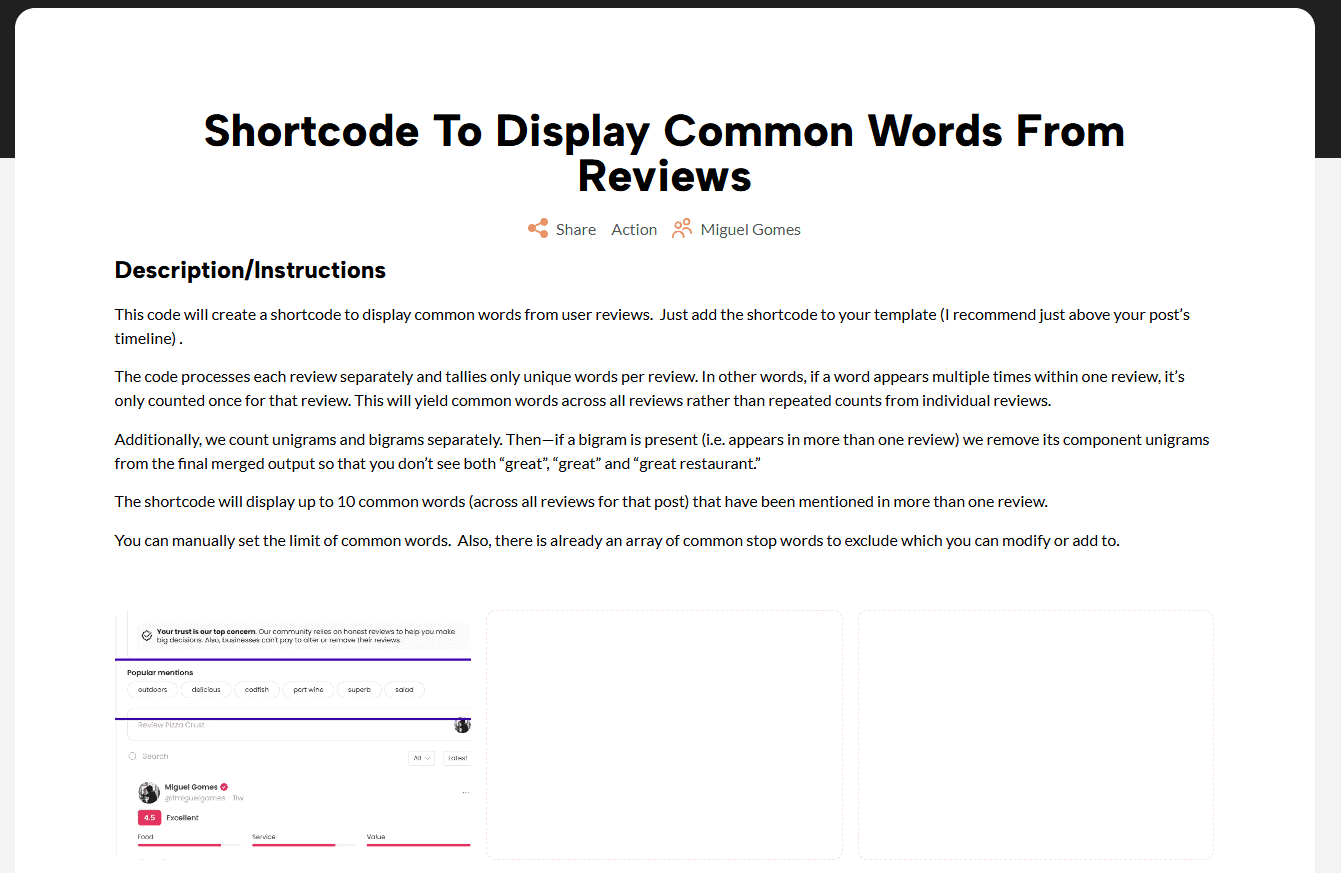
$output = '
';
foreach ( $merged as $phrase => $count ) {
$output .= '' . esc_html( $phrase ) . ' ';
}
$output .= '
';
return $output;
}
add_shortcode( 'common_user_timeline_words', 'voxel_common_user_timeline_words_shortcode' );